Год назад мы играли в Google CTF. В этом году решили не отставать и снова размяться командой старичков. Вообще мы стали чаще играть в CTF, это меня очень радует.
Вообще эта заметка не совсем о таске. Ну то есть о нём, да, но ещё и об одной очень важно и простой мысли. Об этом точно знает любой человек, когда-либо игравший в CTF. CTF — это в первую очередь такой способ узнавать о технологиях, окружающих нас, и о том, как они устроены. Студентам я всегда рассказываю, что выходя с соревнования вы должны ощущать, как много нового вы сегодня узнали. Возможно, ничего не решили, да, но зато узнали-то ого-го!
Так вот о чём это я. Я всегда обходил стороной таски с фотографией каких-нибудь плат и проводов. Я далёк от схемотехники, электричества, да и вообще от физики, так что всегда предпочитал им какие-нибудь более высокоуровневые вещи: типа программирования, веб-безопасности или криптографии. Но рано или поздно это должно было случиться.
Итак, нам дали картинку подключения... эм... какого-то чипа на... эм... какой-то плате к... эм... какому-то устройству (не очень информативно, да, но вы же помните, что я в этом ничего не понимаю?)
Кроме фотографии нам дали 222-мегабайтную CSV-шку: data.7z. Начало у этой CSV-шки примерно такое:
Time [s],Wire6-Analog,Wire7-Analog, Time [s],Wire0-Digital, Time [s],Wire1-Digital, Time [s],Wire2-Digital, Time [s],Wire3-Digital, Time [s],Wire4-Digital, Time [s],Wire5-Digital, Time [s],Wire6-Digital, Time [s],Wire7-Digital
0.000000000000000, 4.768121242523193, 4.773899555206299, 0.000000000000000, 0, 0.000000000000000, 0, 0.000000000000000, 0, 0.000000000000000, 1, 0.000000000000000, 0, 0.000000000000000, 0, 0.000000000000000, 1, 0.000000000000000, 1
0.000008000000000, 4.768121242523193, 4.773899555206299, 0.000000990000000, 1, 0.000065560000000, 1, 0.000194380000000, 1, 0.000451750000000, 0, 0.000452070000000, 1, 0.001480790000000, 1, 1.468471380000000, 0, 2.503182740000000, 0
0.000016000000000, 4.773141384124756, 4.778934478759766, 0.000065230000000, 0, 0.000194070000000, 0, 0.000451450000000, 0, 0.000965990000000, 1, 0.001480440000000, 0, 0.003537600000000, 0, 1.468535670000000, 1, 2.503689840000000, 1
0.000024000000000, 4.773141384124756, 4.773899555206299, 0.000129540000000, 1, 0.000322660000000, 1, 0.000708600000000, 1, 0.001480170000000, 0, 0.002508920000000, 1, 0.005594510000000, 1, 1.472585100000000, 0, 2.507288860000000, 0
0.000032000000000, 4.773141384124756, 4.773899555206299, 0.000193780000000, 0, 0.000451180000000, 0, 0.000965660000000, 0, 0.001994420000000, 1, 0.003537300000000, 0, 0.007651320000000, 0, 1.472649390000000, 1, 2.507799430000000, 1
0.000040000000000, 4.773141384124756, 4.773899555206299, 0.000258100000000, 1, 0.000579770000000, 1, 0.001222810000000, 1, 0.002508600000000, 0, 0.004565780000000, 1, 0.009708230000000, 1, 1.476698830000000, 0, 2.511395640000000, 0
0.000048000000000, 4.778161048889160, 4.778934478759766, 0.000322340000000, 0, 0.000708280000000, 0, 0.001479880000000, 0, 0.003022850000000, 1, 0.005594170000000, 0, 0.011765040000000, 0, 1.476763110000000, 1, 2.511904320000000, 1
Первые полчаса мы занимались двумя вещами: пытались понять, зачем в таблице 9 столбцов со временем, когда можно было сделать один, и гуглили надпись на чипе, к которому подключены клеммы (они же клеммами называются, да?).
Строчки с маркировки гуглятся плохо. Спасает запрос «chip ami 8327», по которому на первом месте выводится страничка «Atari chips». Заодно выясняется, что на чипе написано «CO1», а не «COI», и именно поэтому вторая строчка не гуглилась.
Искомое «CO12294B» на этой странице встречается аж шесть раз, и каждый раз около слова «pokey». Наконец-то можно пойти почитать википедию (это мой любимый момент в каждом таске, ведь именно здесь узнаётся столько нового):
Atari POKEY (Pot Keyboard Integrated Circuit) — электронный компонент, специально разработанная фирмой Atari микросхема генерации звука и интерфейса с устройствами управления. Использовалась в 1980-х годах в ряде игровых систем от Atari — бытовых компьютерах, игровых консолях и аркадных игровых автоматах. Название микросхемы составлено из начальных слогов английских слов POtentiometer и KEYboard, так как эта микросхема часто использовалась для опроса клавиатуры и аналоговых устройств управления (типа paddle). Но в основном, POKEY стала известна благодаря своими возможностями генерации звуковых эффектов и музыки, получив своих поклонников, аналогично микросхемам MOS Technology SID и General Instruments AY-3-8910.
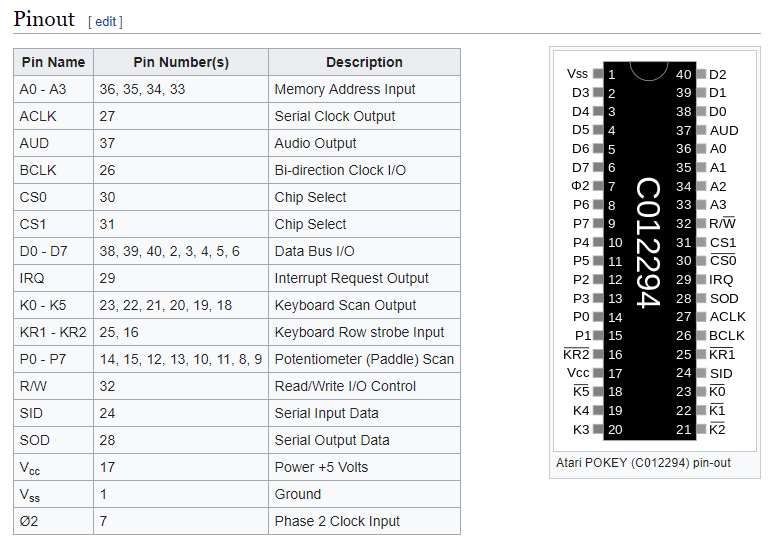
Окей, значит, перед нами либо что-то связанное с клавиатурой, либо что-то, издающее звуки. Поехали на английскую википедию: https://en.wikipedia.org/wiki/POKEY (кстати, картинки в обеих википедиях подсказывают, что мы на правильном пути: там нарисованы именно такие чипы, как у нас). В английской википедии есть распиновка чипа, что для нас очень важно, ведь клеммы подсоединены к конкретным выходам, а не ко всем:
Итак, две клеммы подсоединены к Vss, то есть к земле (по крайней мере, так написано в левой табличке). Остальные восемь — к линиям KR1, KR2, K0, K1, K2, K3, K4 и K5. Первые две, как написано всё в той же табличке, отвечают за «Keyboard Row strobe Input», а остальные шесть — за «Keyboard Scan Output». Ага, всё-таки клавиатура! Про линии K0–K5, вроде, понятно: в статье написано, что поддерживаются клавиатуры до 64 клавиш (+ два модификатора: шифт и контрол), а 64 клавиши — это как раз 6 битов. Вот только что такое остальные две линии и что такое Keyboard Row strobe Input?
Тут мы снова почитали википедию (не стыдно не знать! стыдно не хотеть узнать!): https://en.wikipedia.org/wiki/Data_strobe_encoding. Там написано, что strobe encoding добавляет к линии данных ещё одну линию, причём делает так, чтобы XOR значений на двух линиях менялся каждый такт. Это позволяет синхронизировать такты, а также обнаруживать поломки линии. Ну круто, чо. А почему у нас на шесть линий с данными только две линии с этим strobe? Или это не о том?..
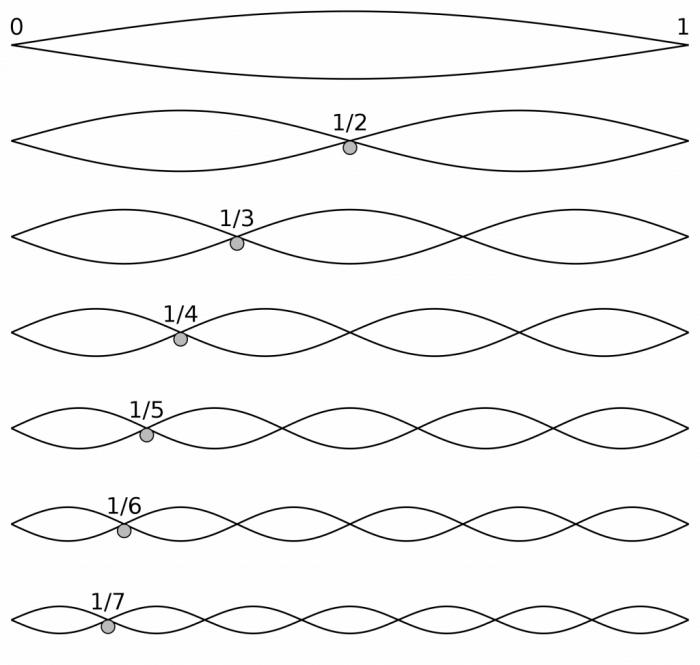
В этом месте мы немного подзастряли, если честно. У нас ведь кроме картинки был ещё 200-мегабайтный CSV-файл с кучей отметок времени, а мы пока за него даже не брались. Поизучаем-ка его более внимательно. Во-первых, кажется, что он состоит из девяти независимых логических колонок: в первой задаётся время и значение (вольтажа?) на двух аналоговых линиях, а в каждой из следующих восьми снова задаётся какое-то время и логическое значение на одной из цифровых линий — нолик или единичка. Вот только почему-то чем дальше, тем логические колонки становятся короче. В первой, например, сотни тысяч записей, сделанных суммарно за 20 секунд, а в последней — только 11. Не 11 тысяч, нет. Просто 11.
Начали смотреть файл ещё внимательнее. Замечаем, что значение каждой логической линии всё время чередуется — то ноль, то единица, потом снова ноль. Предполагаем сразу, конечно, что записывали только изменения значения. Это объясняет и то, почему значений для последней линии так мало: видимо, значение на ней редко менялось. Но почему значение на первой линии так часто меняется? Посчитали — получается около 15 000 раз в секунду. Не может же быть, что кто-то так быстро нажимал на клавиатуре кнопки? Хм, а, может, это тот самый strobe encoding?..
Окей, пока все равно почти ничего не понятно, изучаем файл дальше. Замечаем, что если первая цифровая линия меняет своё значение 15 000 раз в секунду, то вторая — ровно в два раза реже. Удивительно, но третья — ещё в два раза реже! Подозрительно, но всё ещё непонятно :)
Чтоб вы понимали накал страстей: в этот момент мы даже покушали — настолько всё было непонятно!
А после обеда наткнулись на отсканированную версию документации по этим чипам от самой Atari (с грифом CONFIDENTIAL!). Обязательно перейдите по ссылке и полистайте её. С высоты сегодняшних технологий это кажется невероятным трудом:
Ох уж эти написанные на печатной машинке тексты и нарисованные от руки схемы... От них прямо пахнет чем-то волшебным.
В общем, погрузились мы в эту пдфку. А так как в схемотехнике ничего не понимаем, погружаться пришлось очень медленно. Раздел про аудио аккуратно пропустили, перешли сразу к клавиатуре.
Что тут написано: во-первых, линии K0–K5 действительно передают скан-код нажатой клавиши. Брать эти биты надо с отрицанием. В википедии тоже что-то подобное было написано, правда, почему-то отрицание навешано только на K0, K1, K2 и K5:
Интересно, как на самом деле?
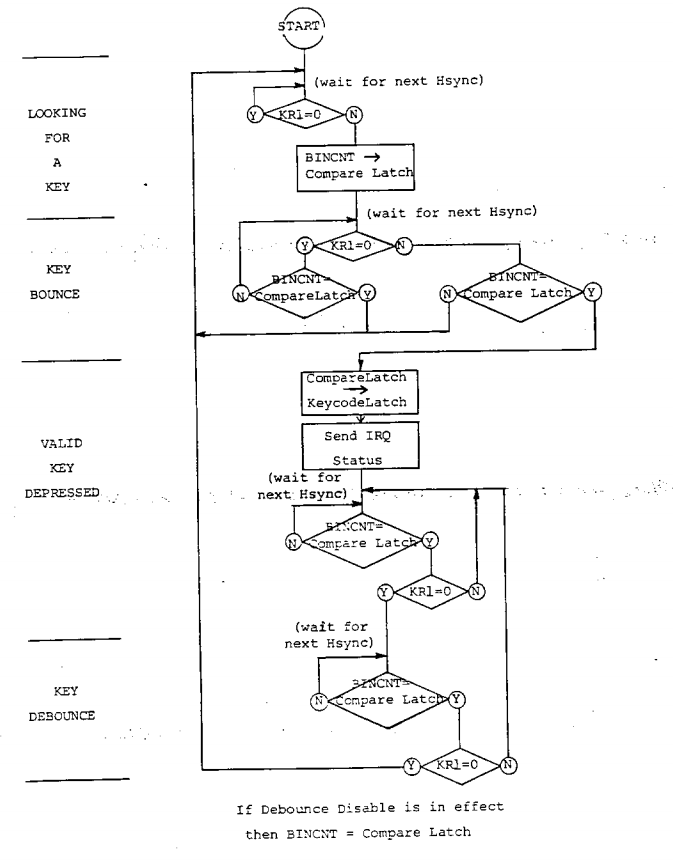
Дальше написано, что внутри чипа POKEY, который уже успел стать нам родным, есть 6-битный счётчик, 6-битный регистр для сравнения, и 8-битный регистр для итогового скан-кода. А дальше идёт абзац, который мы читали (и страдали!) минут двадцать:
Итак, есть некоторый алгоритм для определения, в какой момент сигналы, выставленные на линиях K0–K5, всё-таки являются кодом нажатой клавиши, а когда их не надо слушать. Если отрицание KR1 становится нулём («low» в терминах текста), то значение из счётчика копируется в регистр для сравнения. Дальше происходит некоторая магия для определения того, не было ли это случайностью, и если нажатие клавиши подтверждается на следующем тике, то процессору посылается прерывание, а скан-код нажатой клавиши попадает в специальный регистр. После этого запускается парный алгоритм, не позволяющий создавать прерывания очень-очень часто, пока человек держит кнопку нажатой. На следующей странице пдфки даже есть блок-схема для этого процесса. Мы потратили на неё ещё минут десять:
Окей, но это всё не объясняет, почему у нас значение на линии меняется туда-сюда 15 000 раз за секунду. Ну не нажимают люди так быстро клавиши! Помогла как всегда случайность. Мы нашли ещё одну версию этой документации, причём не только в отсканированном, но и оцифрованном виде: http://krap.pl/mirrorz/atari/homepage.ntlworld.com/kryten_droid/Atari/800XL/atari_hw/pokey.htm.
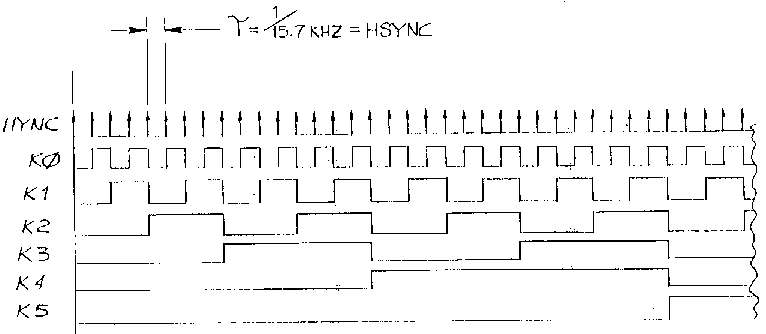
Там был весь тот же текст, что мы уже читали, но вдобавок ещё и интересная картинка:
Во-первых, каждая следующая линия меняет своё значение в два раза реже, чем предыдущая. Прямо, как у нас! Во-вторых, минимальный такт равен 1 / 15.7 kHz, то есть такты тикают 15 700 раз в секунду. Прямо, как у нас [2]!
Благодаря этой картинке появилась гипотеза: значения на каналах K0–K5 меняются вне зависимости от того, нажимал ли человек кнопки, причём меняются именно так, как нарисовано на картинке: каждое следующее меняется в два раза реже, чем предыдущее. И именно это — тот самый strobe encoding, а вовсе не линии KR1 и KR2, как было написано в википедии. А вот когда человек нажимает кнопку на клавиатуре, линии K0–K5 выставляются в правильное положение, а на отрицание KR1 подаётся единица (то есть на самом деле на KR1 подаётся ноль).
Ну что ж, осталось написать код:
def run():
time = 0
last_kr1 = 0
last_scancode = 0
answer = ''
while time < 20:
values = get_values(time)
kr1, kr2, scancode = parse_values(values)
if last_kr1 == 0 and kr1 == 1:
if last_scancode != scancode:
print(f'Current time is {time}, values are {values}')
print(f'kr1 = {kr1}, kr2 = {kr2}, scancode = {scancode}, char = {SCANCODES[scancode]}')
answer += SCANCODES[scancode]
last_scancode = scancode
last_kr1 = kr1
time += HSYNC
print(answer)
В этом коде мы ловим момент, когда отрицание KR1 изменилось с нуля на единицу и выхватываем скан-код, посчитанный из значений K0–K5. Некоторые символы дублировались, потому что по-хорошему надо было реализовать ту самую логику, описанную в пдфке, но это слишком сложно :) Так что просто запоминаем последний скан-код и не повторяем его, если он случился снова.
Вот только где взять таблицу скан-кодов и символов (словарь SCANCODES в коде)? В пдфке её почему-то не было. Зато нужная табличка (как всегда) нашлась где-то в закромах интернета: https://atariwiki.org/wiki/Wiki.jsp?page=KBCODE
Остаётся только перебить его в наше решение, запустить и получить ответ: «FLAG; 8-BIT-HARDWARE-KEYLOGER{CR}». Отправляем, и-и-и, ..., неправильно :( Да ладно, не может быть, фраза-то читаемая получилась. Замечаем одну G в KEYLOGGER и понимаем, что наш алгоритм в данном случае зря выкинул повторение :) Возвращаем вторую G и сдаём ответ.
Полный код решения можно найти на гитхабе.
P.S. Всё-таки оригинальная пдфка была права: надо брать отрицания ко всем линиям, в том числе и к K3, и к K4. А википедия не права.