
Это заметка о том, как мы с Костей Плотниковым решали задание на ассиметричную криптографию с Google CTF, который прошёл неделю назад
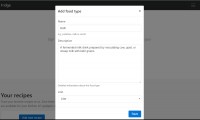
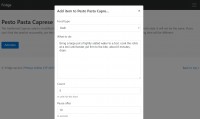
Продолжение истории о необычном поведении юникода и CSV в питоне
Посвящается Полине, которая рассказала мне про странное поведение своей питоновской программы и тем самым подсказала потрясающую идею для сервиса на CTF